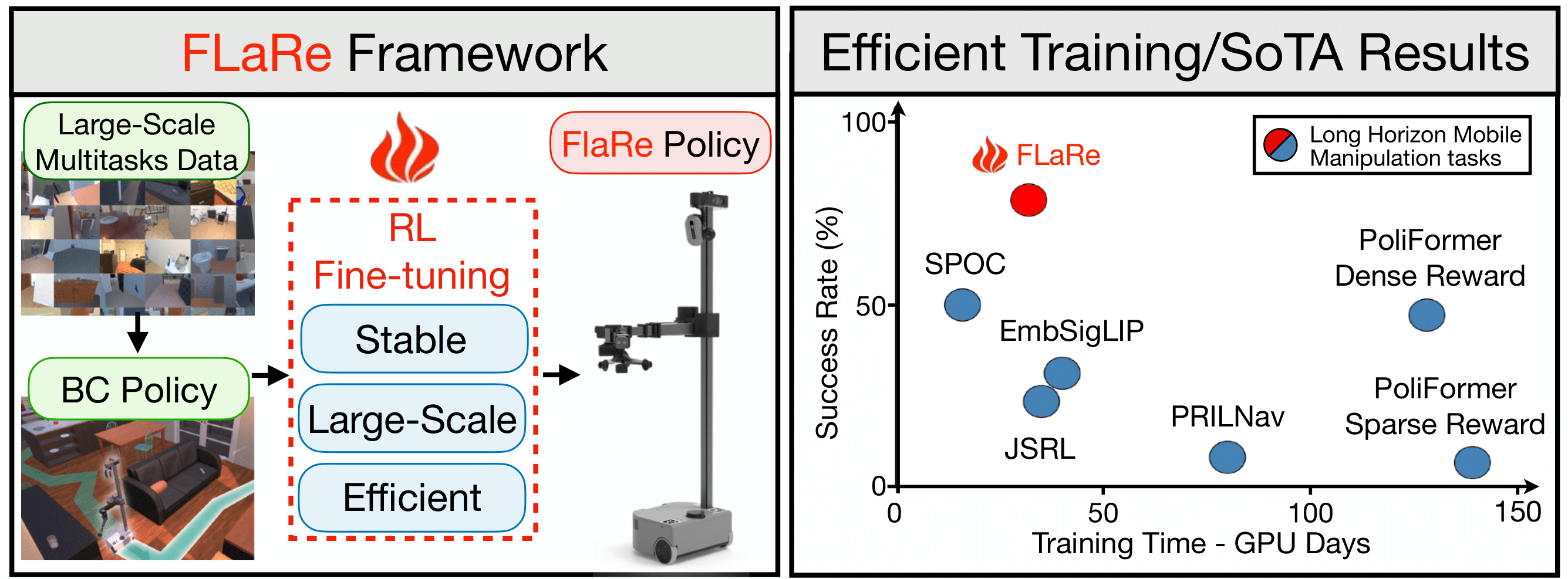
FLaRe fine-tunes transformer BC policies pre-trained on large Robotics datasets with large-scale RL, achieving SoTA results across a set of long-horizon mobile manipulation tasks, in both simulation and real-world. Furthermore, FLaRe shows exceptional adaptation capabilites towards mastering new task capacities, new embodiments, and new objectives efficiently.